Work 25% faster, 40% better: Harvard study finds consulting giant BCG's staff using ChatGPT outperform on every measure – and underachievers get biggest boost

Anna Russell, Ethan Mollick, and Adam Good
ChatGPT can lift capabilities of worst performers and narrow the gap with high achievers according to a study by Harvard Business School but training is crucial. The study, based on tests at management consulting giant Boston Consulting Group, determined that on every task, staff using GPT significantly outperformed their peers, no matter how performance was measured. The AI-powered group completed 12.2 per cent more tasks on average than their peers, while completing tasks 25.1 per cent faster with 40 per cent higher quality results than those without, per one of the study's authors. Large Language Models (LLMs) like ChatGPT seem to particularly outperform on tasks requiring creativity or innovation – sometimes at the expense of accuracy – but underperform on some simple mathematical or logical exercises.
What you need to know:
- Harvard Business School studied the impact of knowledge workers – AKA management consultants – using ChatGPT and found they outperformed their brainiac-for-hire peers on every task measured, no matter how performance was defined.
- Large Language Model (LLMs) also narrowed the gaps between laggards and high performers – the lowest 50 per cent of performers had the biggest uplift.
- Impact was particularly pronounced in areas such as creativity and innovation
- But there were also areas were ChatGPT made things worse.
- And that's before we get to staff development and responsible AI, per the study authors.
AI is weird. No one actually knows the full range of capabilities of the most advanced Large Language Models, like GPT-4. No one really knows the best ways to use them or the conditions under which they fail. There is no instruction manual. On some tasks, AI is immensely powerful, and on others, it fails completely or subtly. And, unless you use AI a lot, you won’t know which is which.
Knowledge workers – i.e. consultants – at BCG using ChatGPT-4 significantly outperformed their colleagues on every dimension measured, and no matter how their performance was calculated, according to a study by Harvard Business School, and the consulting firm.
The data also suggests Large Language Models (LLMs) can narrow the gap between under-performers and high achievers, with the bottom 50 per cent of performers achieving the greatest uplift.
Perhaps unsurprisingly people trained on the LLMs did better than those left to their own devices.
The paper – Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality – also identifies key risks not just in terms of output, but also with implications for staff development and of course, responsible AI.also identifies key risks not just in terms of output, but also with implications for staff development and of course, responsible AI.
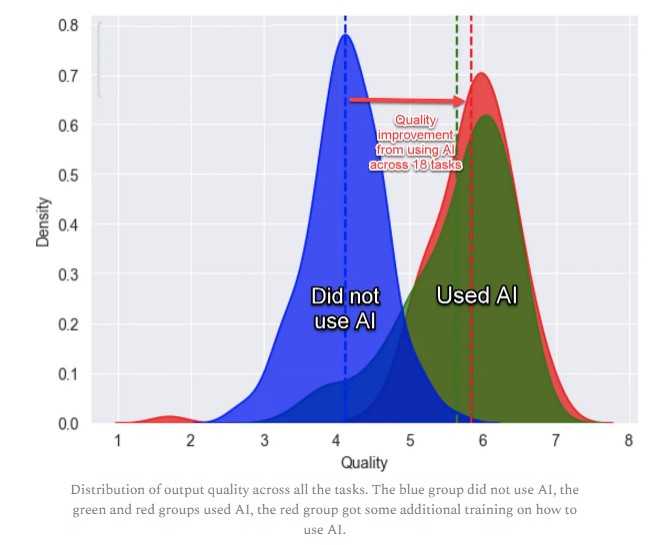
According to one of the authors, Ethan Mollick, writing on his own substack, the consultants represented 7 per cent (approximately 750) of BCG’s total consultant headcount. They were measured across 18 tasks that typically represent the work they do.
“Consultants using ChatGPT-4 outperformed those who did not, by a lot. On every dimension. Every way we measured performance," per Mollick.
He said the AI-powered group completed 12.2 per cent more tasks on average than their peers, and they also "completed tasks 25.1 per cent more quickly, and produced 40 per cent higher quality results than those without.”
The authors of the paper coined the phrase – the Jagged Frontier – to describe the somewhat unruly experience of using AI.
As Mollick noted in his blog: “AI is weird. No one actually knows the full range of capabilities of the most advanced Large Language Models, like GPT-4. No one really knows the best ways to use them or the conditions under which they fail. There is no instruction manual. On some tasks, AI is immensely powerful, and on others, it fails completely or subtly. And, unless you use AI a lot, you won’t know which is which.”
The result, per Mollick, is the “Jagged Frontier” of AI. "Imagine a fortress wall, with some towers and battlements jutting out into the countryside, while others fold back towards the centre of the castle. That wall is the capability of AI, and the further from the centre, the harder the task. Everything inside the wall can be done by the AI, everything outside is hard for the AI to do.”
The problem, according to Mollick, is that the wall is invisible.
Expect the unexpected
The study found that the ability of LLMs to complete tasks to a human or better standard is highly variable, and not necessarily what would be expected based on human perception of task difficulty.
Anna Russell, a Sydney data analytics consultant and director of Polynomial Solutions who has worked with organisations such as Reserve Bank of Australia, St George Bank, and CoreLogic, reviewed the paper for Mi3 Australia. “The implication of this is that we must be quite careful when utilising LLMs for a task, and understand whether the task sits inside this capability frontier or not," said Russell. "Interestingly LLMs seem to outperform on tasks requiring creativity or innovation – sometimes at the expense of accuracy – but underperform on some simple mathematical or logical exercises.”
Russell told Mi3 that for tasks that sit inside the frontier such as creative product ideation, LLMs were widely beneficial as a tool for AI-assisted task completion, improving participant output quality as well as productivity.
“Although all levels of participants showed improved performance, the uplift from LLMs was greater for the bottom 50 per cent of performers than for the high achievers. Also, uplift was better when participants were trained in how to use the LLMs effectively (prompt engineering) than when they were left to their own devices. This highlights the importance of providing quality instructions when using AI tools.
It's just a jump to the right Pic: Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality
Risky business
The study revealed some important limitations – and risks – according to Russell.
“For tasks outside the frontier, the impact of LLMs was dangerous. Participants exhibited increased productivity: 18 per cent for those using the LLM without prompt engineering training, and 30 per cent-plus for those who were trained how to use it effectively."
But accuracy declined significantly, adding a significant caveat to those headline figures.
"The problematic part is that the quality of the responses was higher, but the correctness of the responses was poorer. A dangerous combination,” she said.
The paper also ponders the implications of embedding AI in high-skill environments, noting for instance that if tasks inside the frontier are delegated to an AI, then junior-level employees lose the opportunity to develop skill via these tasks, which may create long-term training and skill deficits in the future.
Then there is the not inconsiderable issue of responsible AI, especially for high-risk and high-implication issues as machines do not apply human value judgments to their decisions.
True story?
For Adam Good, previously executive director of marketing technology for WPP and now an investor and advisory board member for Mozaik Play, the findings in the paper were borne out by his own experiences at the holdco.
“We ran ChatGPT trials with creative agencies, mostly looking at whether we could deliver improvements to ideation and get the ideas onto the table faster. We treated ChatGPT like a junior team member doing research or other process-driven tasks, and it proved to be really good.”
But, he cautioned, “You need to vet accuracy very early before it goes into an AI dream state, where you risk destroying the foundations of your work by iterating early mistakes.”
He said the firm also saw a big improvement with the arrival of ChatGPT-4, which allowed it to ingest things like PDFs, mind maps, and flow charts.
“When you look at where it’s going it's going to continue to improve.”
Good told Mi3 the impact on knowledge workers at a firm like BCG was not surprising.
“You mostly go to firm like that, to consultants, for research and hypothesis so it makes sense. It will do work that in the past might have taken two weeks in a few keystrokes – as long as it's not hallucinating.”
He also said the capacity of LLMs to make mistakes, or to simply make things up demonstrated the value consultants operating at a strategic level bring to a business.
“They are going to be more important as they can call out the bullshit or at least challenge it early within the realm of experience they have acquired.”